LLM・AIモデル開発において、マルチノードGPUクラスタの構築需要が高まっています。当社は、ハードウェアの手配から、ネットワーク、ジョブ管理ソフトウェアの導入まで、協力パートナーと連携し、お客様のAI開発環境づくりを総合的にサポートします。
Supported Technologies
The Challenge
複数台のGPUサーバーを利用する環境では、単にサーバーを並べるだけでは期待する処理速度は得られません。モデルの学習や推論を高速に処理するためには、複数のレイヤーを適切に統合する必要があります。
従来のネットワーク設計では、AI特有の大きなトラフィックに対応できず、通信の渋滞(輻輳)を引き起こす可能性があります。
サーバー、ストレージ、ネットワークなど各要素が分断されがちで、設定や構築の難易度が高くなっています。
GPUの管理が個人・部門単位となり、リソースを効率的に共有・活用するためのソフトウェアの選定・導入が壁となります。
データ転送効率を高めるための、ネットワーク設定および結線作業を確実に行います。
複数ユーザー間でリソースを共有するための、ジョブスケジューラ等のソフトウェア導入・初期設定を支援します。
ラッキングからOSインストールまで、運用開始に必要なインフラ環境を一気通貫で整えます。
Our Services
高度なGPUクラスタの性能を引き出すための技術要件(最適な通信経路の確保や動的ルーティングなど)を考慮し、当社および協力パートナーにて以下の設定・構築作業を実施いたします。
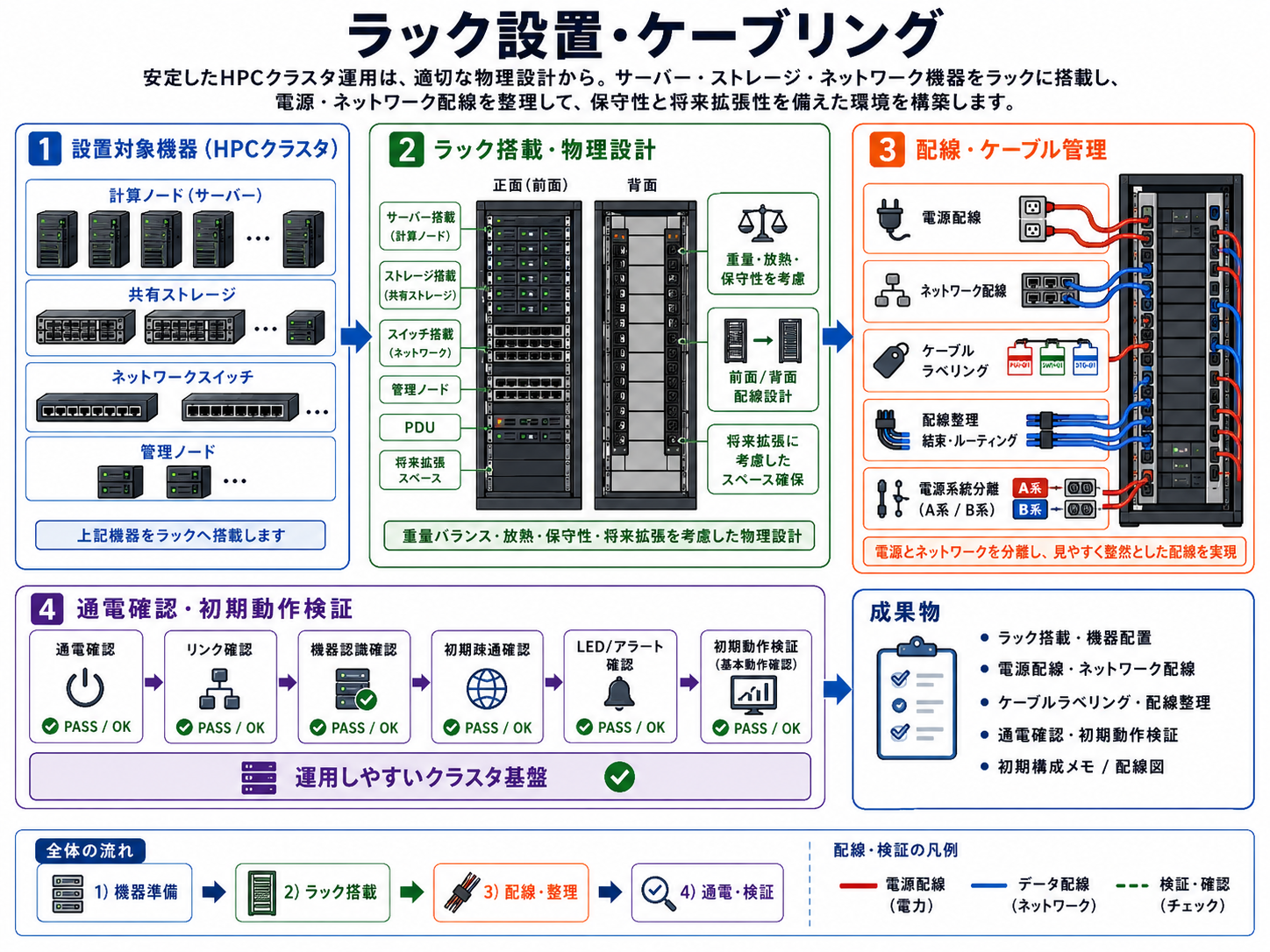
HPCクラスタの安定運用は、適切な物理設計から始まります。サーバー、ストレージ、ネットワーク機器をラックへ搭載し、将来的なノード追加やメンテナンス性も考慮した配線設計を実施。電源系統やケーブル管理まで含め、運用しやすいクラスタ基盤を構築します。
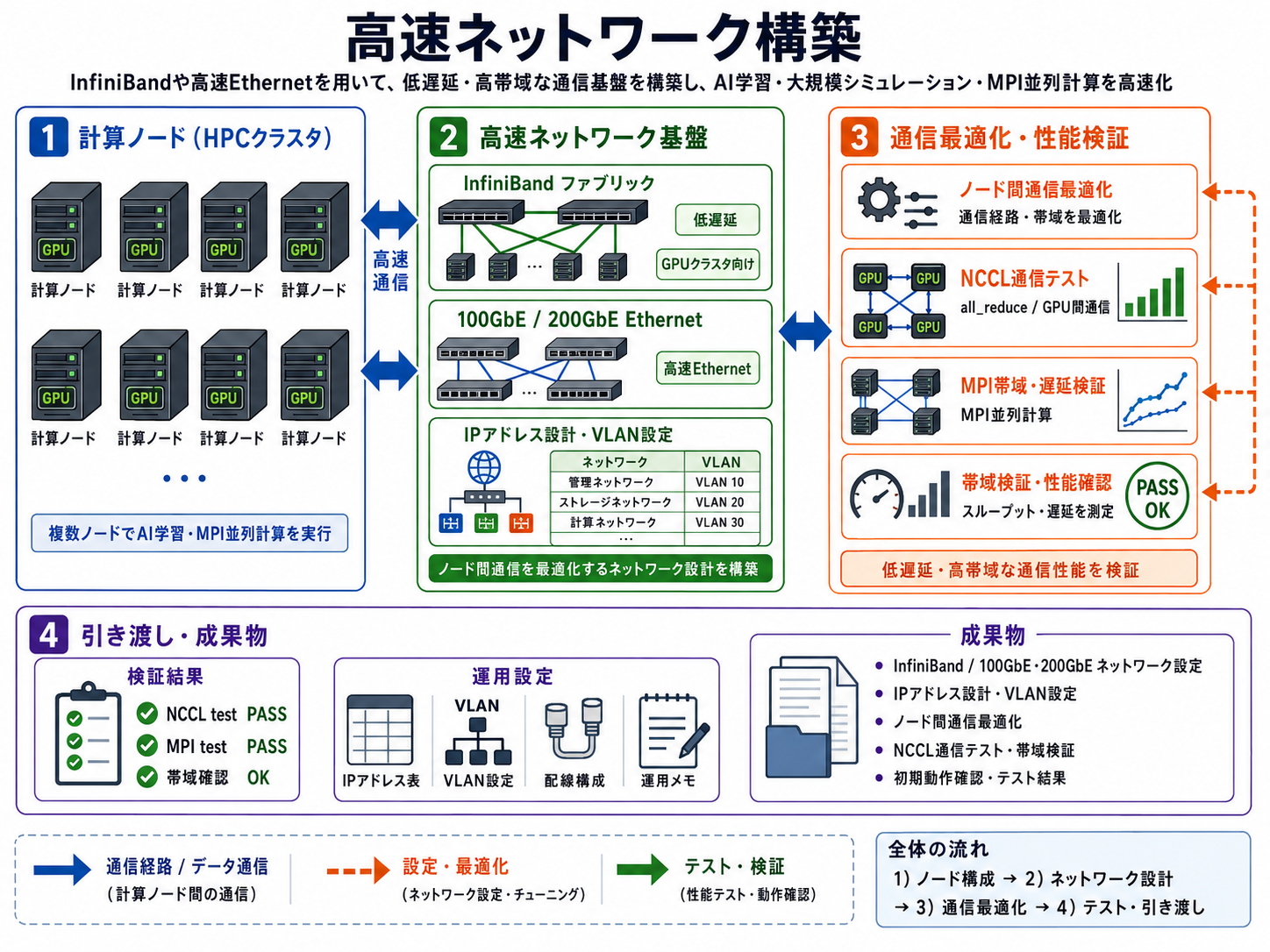
AI学習や大規模シミュレーションでは、ノード間通信性能がシステム全体の処理速度を左右します。InfiniBandや高速Ethernetを用いた低遅延・高帯域なネットワークを構築し、GPUクラスタやMPI並列計算環境に最適な通信基盤を実現します。
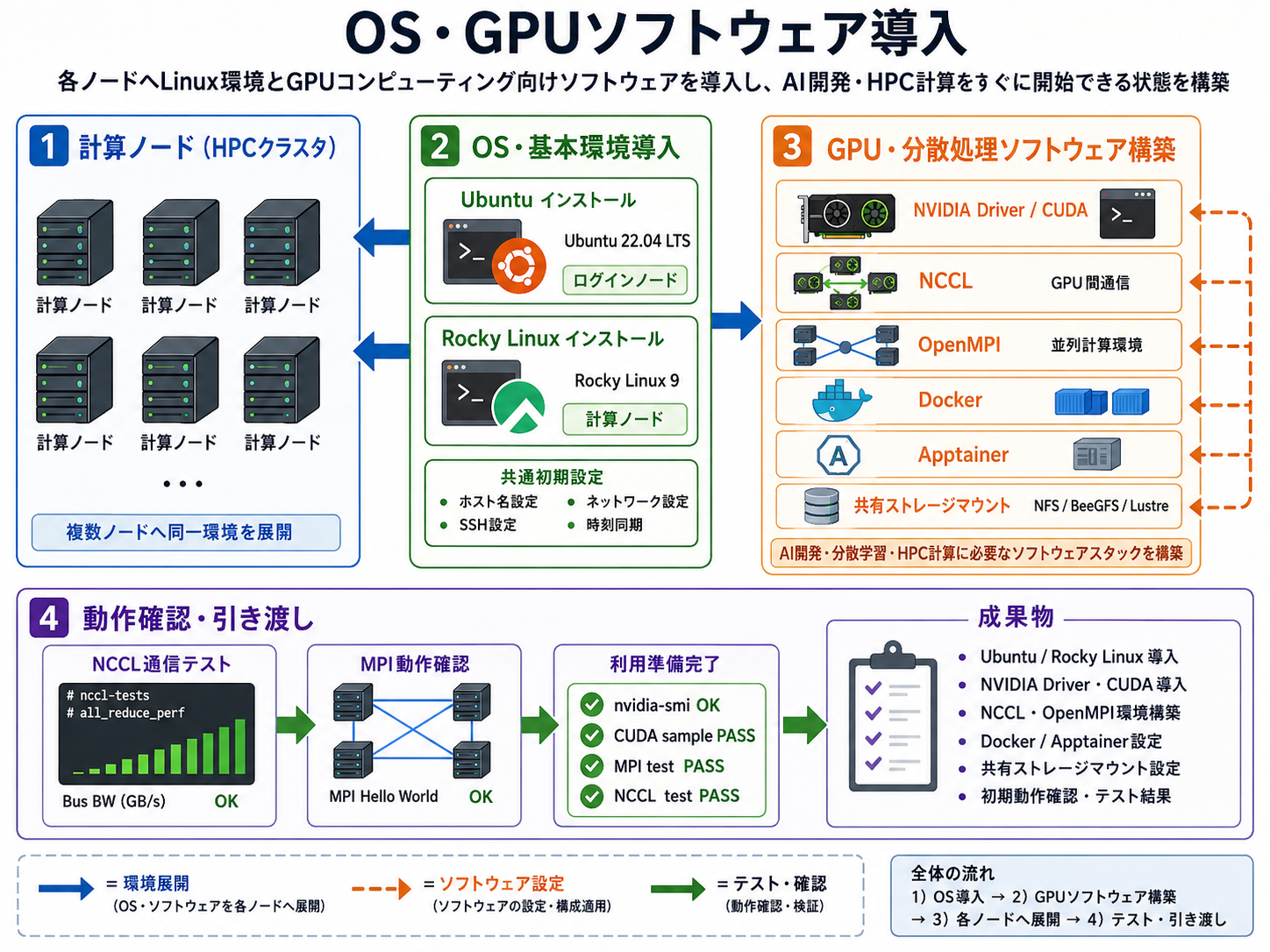
各ノードへLinux環境を導入し、GPUコンピューティングや分散学習に必要なソフトウェアスタックを構築します。CUDAやNCCL、MPI環境まで含めてセットアップを行い、導入後すぐにAI開発やHPC計算を開始できる状態でお引き渡しします。
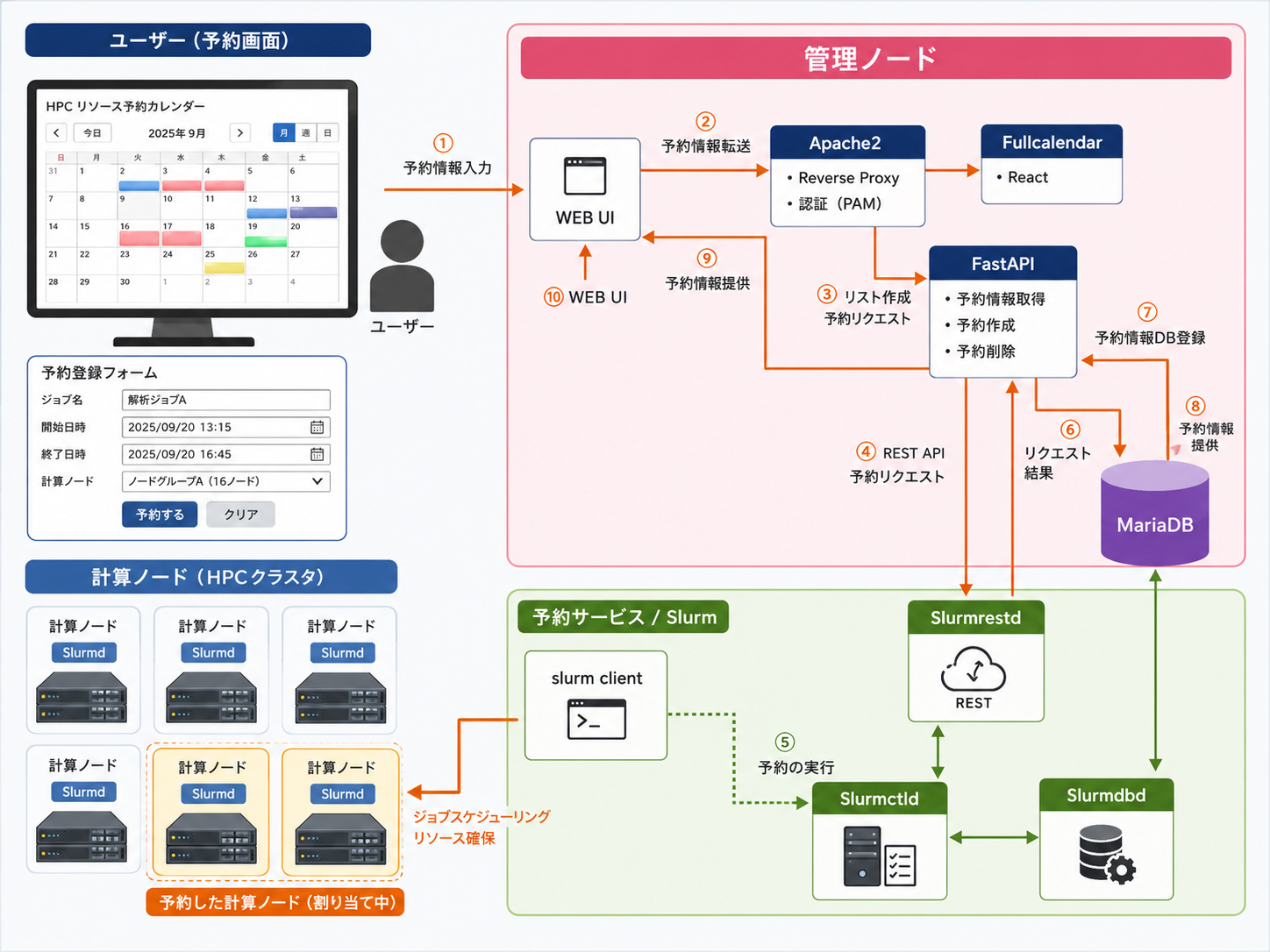
複数ユーザーや複数プロジェクトで計算資源を効率よく共有するため、ジョブスケジューラを導入します。GPUやCPUリソースを適切に割り当てることで、研究開発部門やAI開発チームが公平かつ効率的に利用できる運用環境を実現します。
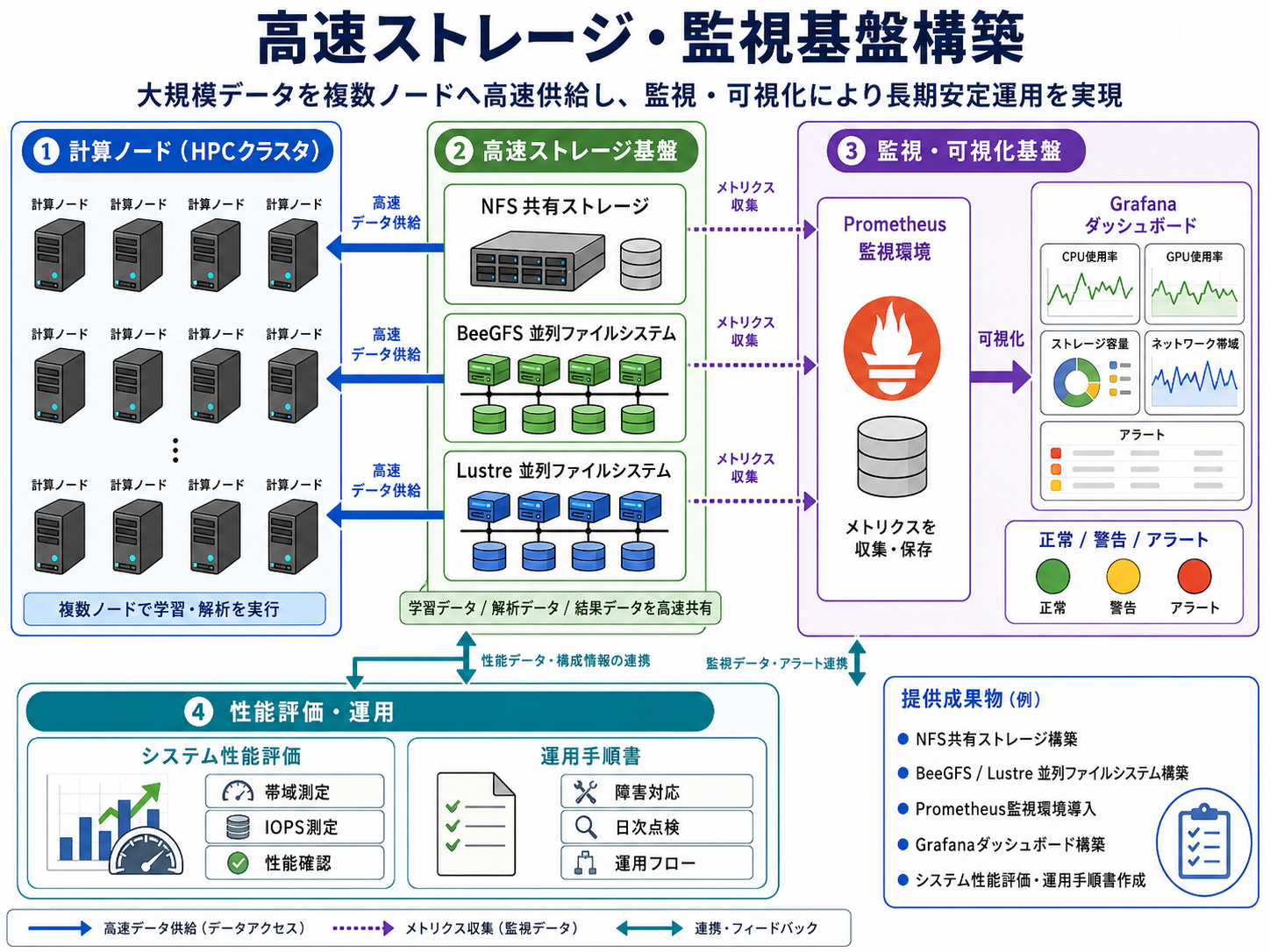
大規模な学習データや解析データを複数ノードへ高速供給するため、高性能ストレージ環境を構築します。また、システムの稼働状況やリソース使用率を可視化する監視基盤を整備し、長期的に安定運用できる環境をご提供します。
LLMや生成AIの開発・運用には、従来とは桁違いの計算量とデータ処理能力が求められます。単にハイエンドGPUを搭載するだけでなく、CPU構成、メモリ容量、高速ストレージ、ネットワークまで、「実際に性能が出る構成・安定して運用できる構成」を重視した設計が当社の強みです。
単体のAIワークステーションから、複数GPUを搭載したAIサーバー、さらにはスケールアウト可能なクラスター環境まで、お客様の開発規模や運用形態に合わせて最適なハードウェアをご提案いたします。

サーバー、ネットワーク、ソフトウェアなど多岐にわたる設定項目について、専門知識を持つパートナーと連携し、ハードウェア構成のご提案から運用スタートまでの各フェーズをサポートいたします。